
Niedawna globalna awaria systemów Microsoft wywarła ogromny wpływ na wiele sektorów gospodarki na całym świecie. Problemy z platformą Azure spowodowały zakłócenia w działaniu Microsoft 365, co wpłynęło na funkcjonowanie przedsiębiorstw, lotnisk, szpitali, giełdy i wielu innych instytucji. To wydarzenie podkreśliło, jak ważne jest odpowiednie zarządzanie i utrzymanie infrastruktury IT oraz rola specjalistów DevOps w zapewnianiu ciągłości działania systemów informatycznych. W niniejszym artykule przeanalizujemy skutki awarii oraz wnioski, jakie z niej płyną.

Globalna awaria systemów Microsoft
Niedawna awaria systemów Microsoft miała globalny zasięg i znacząco wpłynęła na wiele aspektów naszego codziennego życia. Problemy dotknęły nie tylko indywidualnych użytkowników, ale również kluczowe sektory, takie jak lotnictwo, bankowość i służba zdrowia. Co ważne, awaria była wynikiem dwóch niezależnych zdarzeń: problemów technicznych związanych z platformą chmurową Azure oraz błędem w aktualizacji oprogramowania CrowdStrike.
Problemy z Azure i Microsoft 365
Platforma Azure, zbiór serwerowni dostarczających usługi chmurowe, napotkała problemy w jednej z serwerowni – US Central. W wyniku tej awarii, usługi Microsoft 365 przestały działać, ponieważ oprogramowanie nie było w stanie szybko przełączyć się na inną serwerownię, np. US West. Przerwa w działaniu tej jednej serwerowni miała ogromny wpływ na wiele firm i instytucji, które miały swoją infrastrukturę opartą właśnie o US Central.
Skutki awarii Azure
Awaria serwerowni US Central wpłynęła na działanie lotnisk i innych elementów życia publicznego. Przykładowo, linie lotnicze, które miały swoje bazy danych i infrastrukturę opartą tylko o US Central, nie mogły przełączyć się na inne serwerownie, co doprowadziło do zakłóceń w działaniu systemów zarządzania lotami i opóźnień w obsłudze pasażerów.
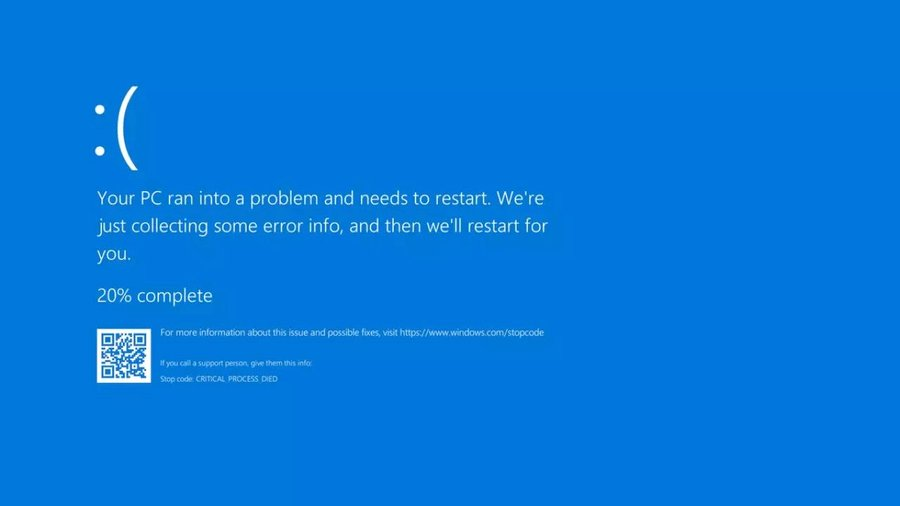
Niebieskie ekrany śmierci – CrowdStrike
Oprócz problemów z Azure, użytkownicy systemu Windows doświadczyli problemów z powodu błędu w aktualizacji oprogramowania CrowdStrike. Błąd ten spowodował pojawienie się „niebieskich ekranów śmierci” na wielu komputerach, uniemożliwiając ich normalne funkcjonowanie. Firmy korzystające z oprogramowania CrowdStrike powinny lepiej zabezpieczyć proces pobierania aktualizacji, aby uniknąć takich sytuacji. Ważną rolę odgrywają tu dyrektorzy ds. sieci, którzy powinni zapewnić, że infrastruktura IT jest odpowiednio rozproszona i chroniona przed wadliwymi aktualizacjami. Proces pobierania aktualizacji powinien być lepiej zabezpieczony i przemyślany, aby wadliwy kod nie oddziaływał na krytyczną infrastrukturę.
Reakcje i działania w obliczu awarii
Podczas całego zdarzenia, zespoły IT na całym świecie musiały szybko reagować, aby zminimalizować skutki awarii. Firmy, które najlepiej poradziły sobie z kryzysem, to te, które miały rozproszoną infrastrukturę IT i mogły przełączyć się na alternatywne serwerownie. Takie podejście umożliwia szybkie przywrócenie normalnego funkcjonowania systemów i minimalizowanie zakłóceń. Ważne jest jednak zrozumienie, że to rozwiązanie pomagało tylko w przypadku awarii serwerowni, a nie błędu oprogramowania CrowdStrike.
Rozproszona infrastruktura oznacza, że firma ma swoje dane i aplikacje rozmieszczone w różnych lokalizacjach. Przykładem może być linia lotnicza, której systemy rezerwacyjne i bazy danych są rozmieszczone w serwerowniach US Central i US West. Gdy serwerownia US Central przestała działać, systemy mogły automatycznie przełączyć się na serwerownię US West, dzięki czemu operacje lotnicze mogły być kontynuowane bez większych zakłóceń. Taka elastyczność minimalizuje przerwy w działaniu i pozwala na szybkie przywrócenie normalnych operacji.
Niestety, to rozwiązanie nie pomaga w przypadku błędu oprogramowania, takiego jak ten, który wystąpił z CrowdStrike. Błąd ten spowodował pojawienie się „niebieskich ekranów śmierci” na komputerach użytkowników, co uniemożliwiło ich normalne funkcjonowanie. Nawet jeśli firma posiada rozproszoną infrastrukturę, błąd oprogramowania wpływa na wszystkie komputery, na których zainstalowano wadliwą aktualizację. Dlatego tak ważne jest, aby firmy miały dobrze przemyślane procedury aktualizacji oprogramowania, które pozwalają na dokładne testowanie nowych wersji przed ich wprowadzeniem do użytku.
Komunikaty dla użytkowników
Podczas awarii komunikacja z użytkownikami była kluczowa, aby minimalizować panikę i zapewnić przejrzystość działań naprawczych. Zarówno Microsoft, jak i CrowdStrike, regularnie przekazywali informacje na temat statusu naprawy, co pozwoliło utrzymać zaufanie klientów.
Komunikaty Microsoft
Rzeczniczka Microsoft Polska, Anna Klimczuk, zapewniała, że firma dokłada wszelkich starań, aby jak najszybciej rozwiązać problem. Microsoft na bieżąco informował użytkowników o postępach prac nad przywróceniem pełnej funkcjonalności usług Microsoft 365 i platformy Azure. Regularne aktualizacje były publikowane w mediach społecznościowych, co pozwoliło użytkownikom na bieżąco śledzić sytuację.
Komunikaty CrowdStrike
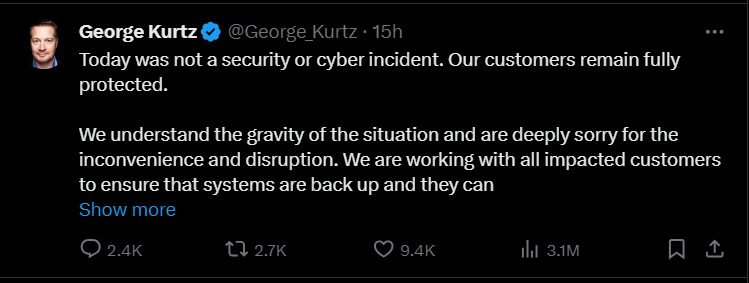
George Kurtz, CEO firmy CrowdStrike, opublikował wpis na platformie X, w którym podkreślił, że awaria nie była związana z incydentem bezpieczeństwa ani cyberatakiem. „Dziś nie doszło do incydentu związanego z bezpieczeństwem ani cyberataku. Nasi klienci są w pełni chronieni,” napisał Kurtz. Dodał również, że firma zdaje sobie sprawę z powagi sytuacji i przeprasza za niedogodności i zakłócenia. „Współpracujemy ze wszystkimi dotkniętymi klientami, aby zapewnić przywrócenie systemów,” zaznaczył Kurtz.
Znaczenie rozproszonej infrastruktury
Awaria systemów Microsoft uwidoczniła, jak kluczowe jest posiadanie rozproszonej infrastruktury IT. Firmy, które nie opierały całej swojej infrastruktury na jednej serwerowni, lepiej poradziły sobie z awarią, mogąc szybko przełączyć się na alternatywne lokalizacje.
Minimalizacja zakłóceń
Rozproszenie infrastruktury pozwala na szybsze przywrócenie normalnego funkcjonowania systemów. Dzięki temu firmy mogą minimalizować zakłócenia w działaniu i zapewniać ciągłość operacji. Posiadanie danych i aplikacji w różnych lokalizacjach umożliwia dynamiczne zarządzanie zasobami i zmniejsza ryzyko całkowitego przestoju.
Przewaga elastyczności
Firmy, które posiadały elastyczną infrastrukturę, mogły szybciej reagować na awarie. Rozproszenie danych i aplikacji w różnych lokalizacjach pozwala na dynamiczne zarządzanie zasobami i zmniejsza ryzyko całkowitego przestoju.
Specjaliści DevOps
Awaria ta również podkreśliła znaczenie posiadania wykwalifikowanych specjalistów DevOps. Dzięki automatyzacji i ciągłemu monitorowaniu systemów, DevOpsi mogą wcześniej wykrywać problemy i zapobiegać ich eskalacji.
Automatyzacja i monitorowanie
Lepsze procedury DevOps mogłyby zminimalizować wpływ awarii na firmy i użytkowników na całym świecie. Automatyzacja procesów oraz ciągłe monitorowanie systemów pozwala na szybkie identyfikowanie i rozwiązywanie problemów, zanim staną się poważne. Przykładowo lepszy proces pobierania i testowania aktualizacji oprogramowania zewnętrznego mógłby pomóc wielu instytucjom wyeliminować pojawienie się „niebieskiego ekranu śmierci” w kluczowej infrastrukturze.
Zarządzanie kryzysowe
DevOpsi odgrywają kluczową rolę w zarządzaniu kryzysowym. Dzięki swojej wiedzy i umiejętnościom, mogą szybko wdrażać rozwiązania i minimalizować negatywne skutki awarii. Ich działania są niezbędne do utrzymania stabilności i bezpieczeństwa infrastruktury IT.
Wnioski z globalnej awarii Microsoft
Globalna awaria w systemach Microsoft uwidoczniła wiele istotnych lekcji dla firm technologicznych. Problemy z Azure i Microsoft 365 podkreśliły znaczenie solidnych procedur zarządzania kryzysowego oraz posiadania rozproszonej infrastruktury IT.
Firmy muszą inwestować w rozwój i wdrażanie solidnych procedur zarządzania kryzysowego. Dobre przygotowanie i szybka reakcja na awarie są kluczowe dla minimalizowania skutków przestojów. Oznacza to, że firmy powinny regularnie przeprowadzać testy i symulacje awaryjne, aby upewnić się, że ich plany są skuteczne. Ważne jest również, aby zespół zarządzania kryzysowego był dobrze przeszkolony i zawsze gotowy do działania. Regularna aktualizacja i przegląd procedur zarządzania kryzysowego pomaga w adaptacji do zmieniających się zagrożeń i technologii. Inwestowanie w solidne procedury zarządzania kryzysowego jest niezbędne dla zapewnienia ciągłości operacji i ochrony przed nieprzewidzianymi zdarzeniami.
Podsumowanie
Awaria systemów Microsoft to lekcja dla nas wszystkich. Pokazała, że posiadanie rozproszonej infrastruktury IT jest nie tylko korzystne, ale wręcz konieczne. Firmy, które miały zapasowe serwerownie, mogły szybko przełączyć się na inne lokalizacje, minimalizując przestoje. To pokazuje, jak ważne jest bycie przygotowanym na niespodziewane incydenty.
Również rola specjalistów DevOps okazała się kluczowa. Dzięki ich wiedzy i umiejętnościom firmy mogły szybko wykrywać problemy i wdrażać rozwiązania, zanim te miały szansę eskalować. W świecie IT, gdzie każda minuta przestoju kosztuje, specjaliści DevOps są niezastąpieni.



